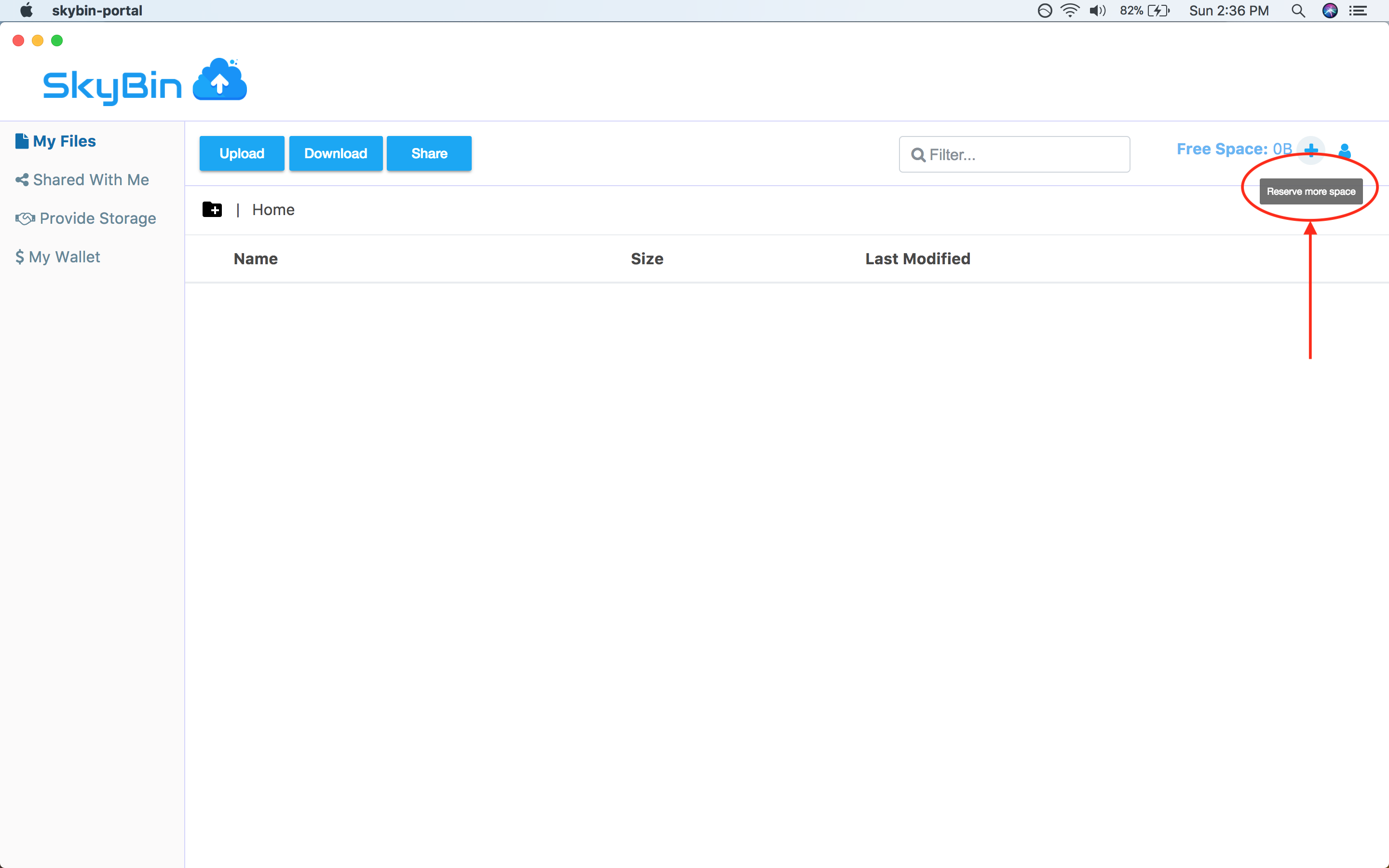
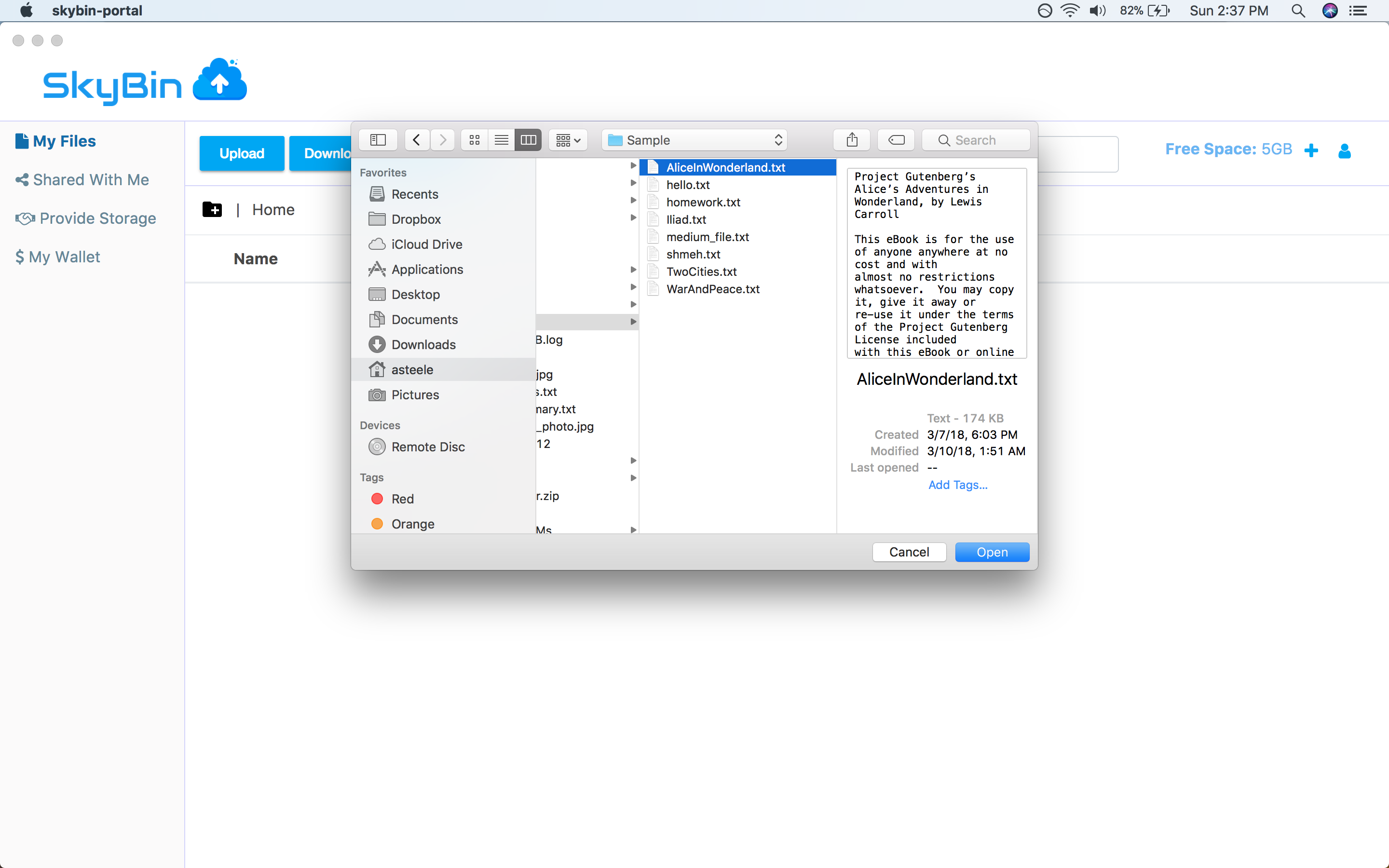
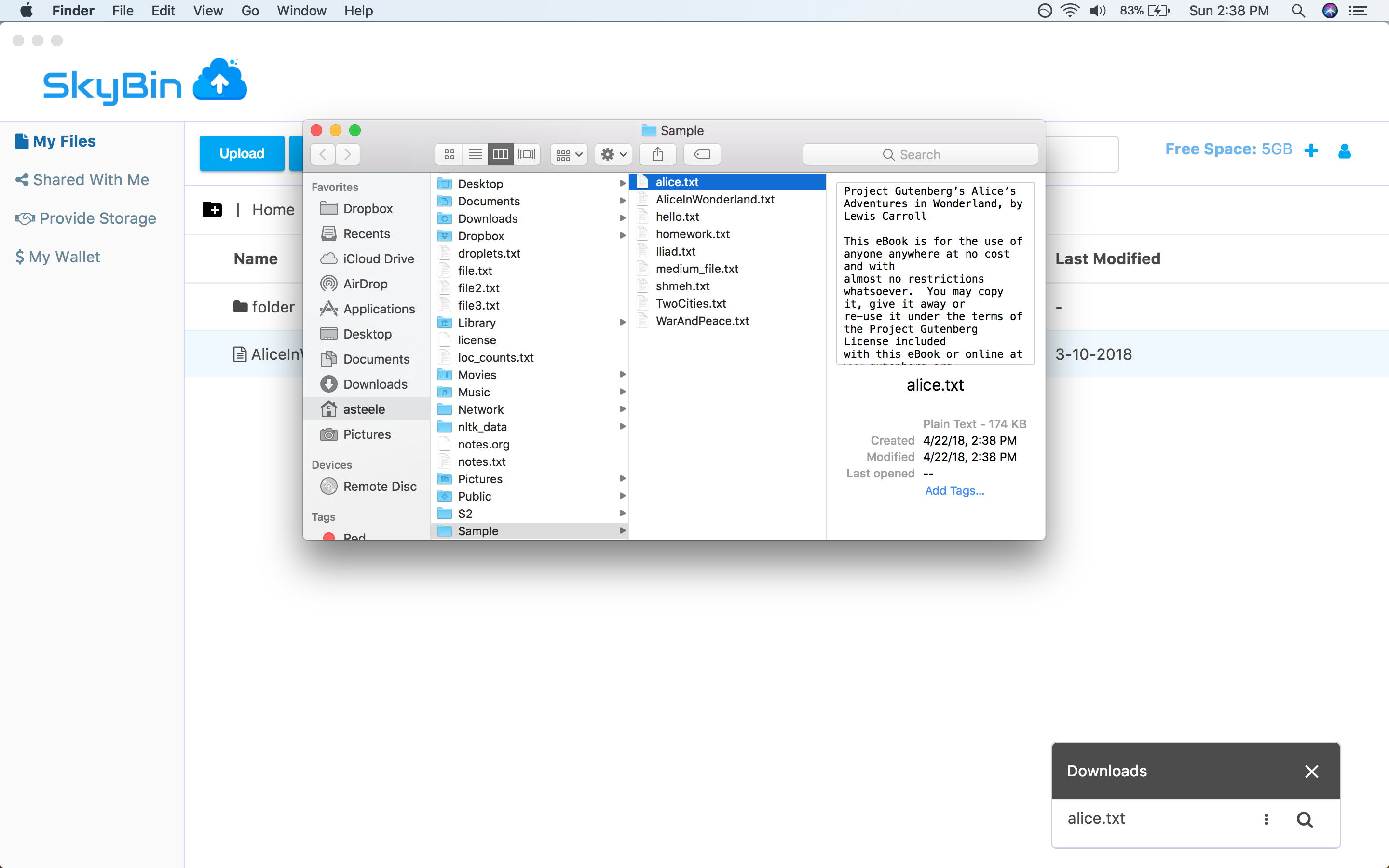
SkyBin is a peer-to-peer file storage application. Just like other online
storage apps, it lets you store your files online, share them with people you
know, and access them from multiple computers. The difference is that SkyBin is
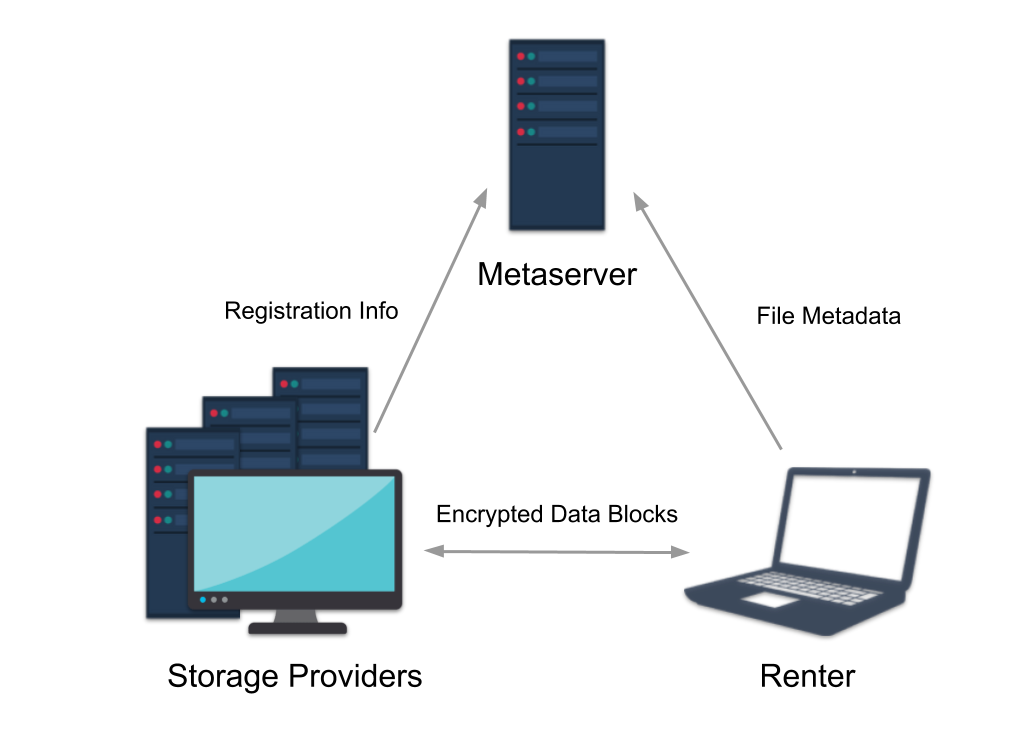
powered by a peer-to-peer storage network instead of a central service. So when
you store a file in SkyBin, it gets placed on other users' machines, not on servers
operated by SkyBin.
This means that storage on SkyBin can be cheap, but it's also designed to be
secure and reliable. SkyBin encrypts your files end-to-end and guards against
data loss and corruption through periodic storage audits and redundant storage
built on a technique called erasure coding. These features allow the system
to recover your content even if other users go offline or try to tamper with
your files.
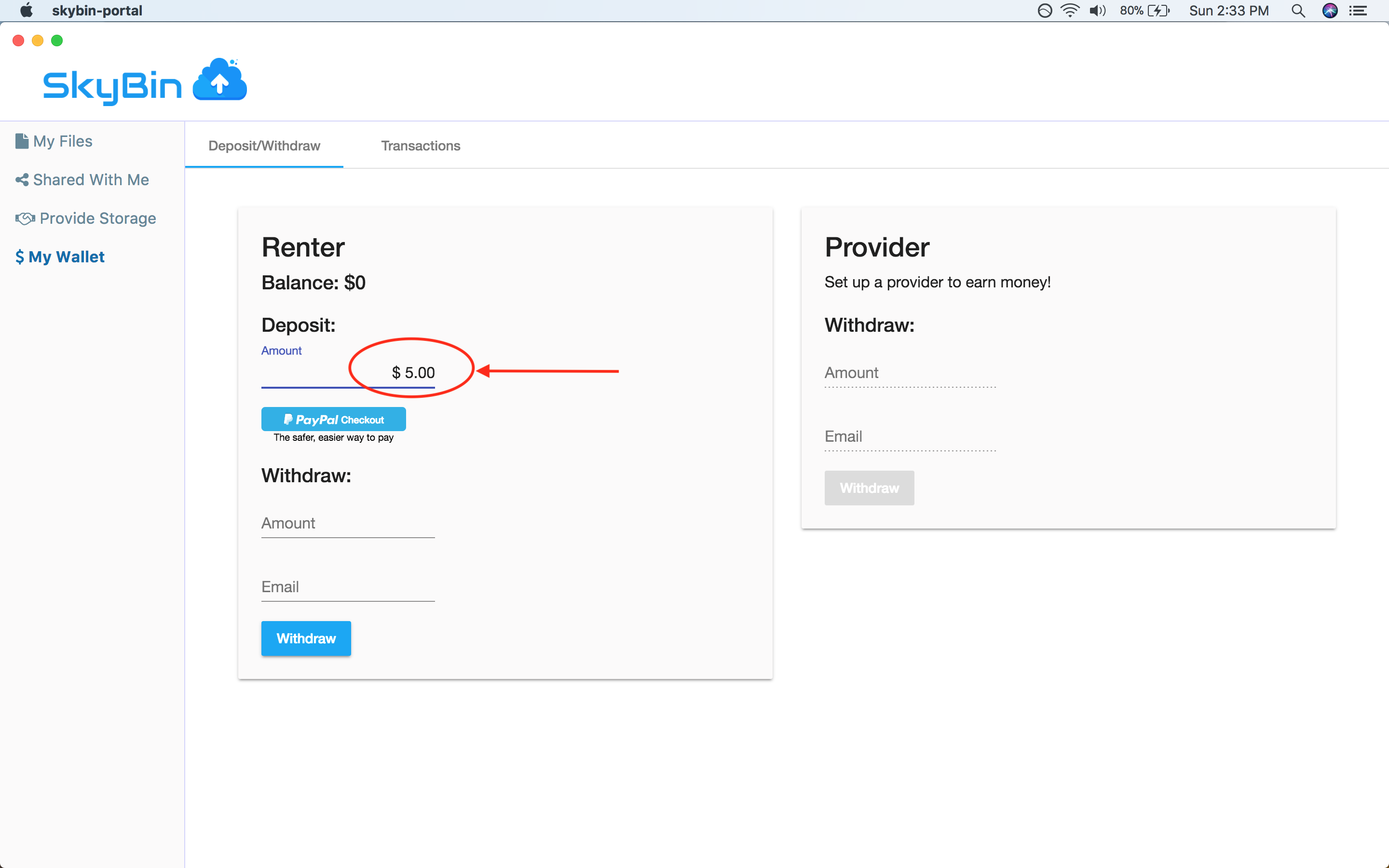
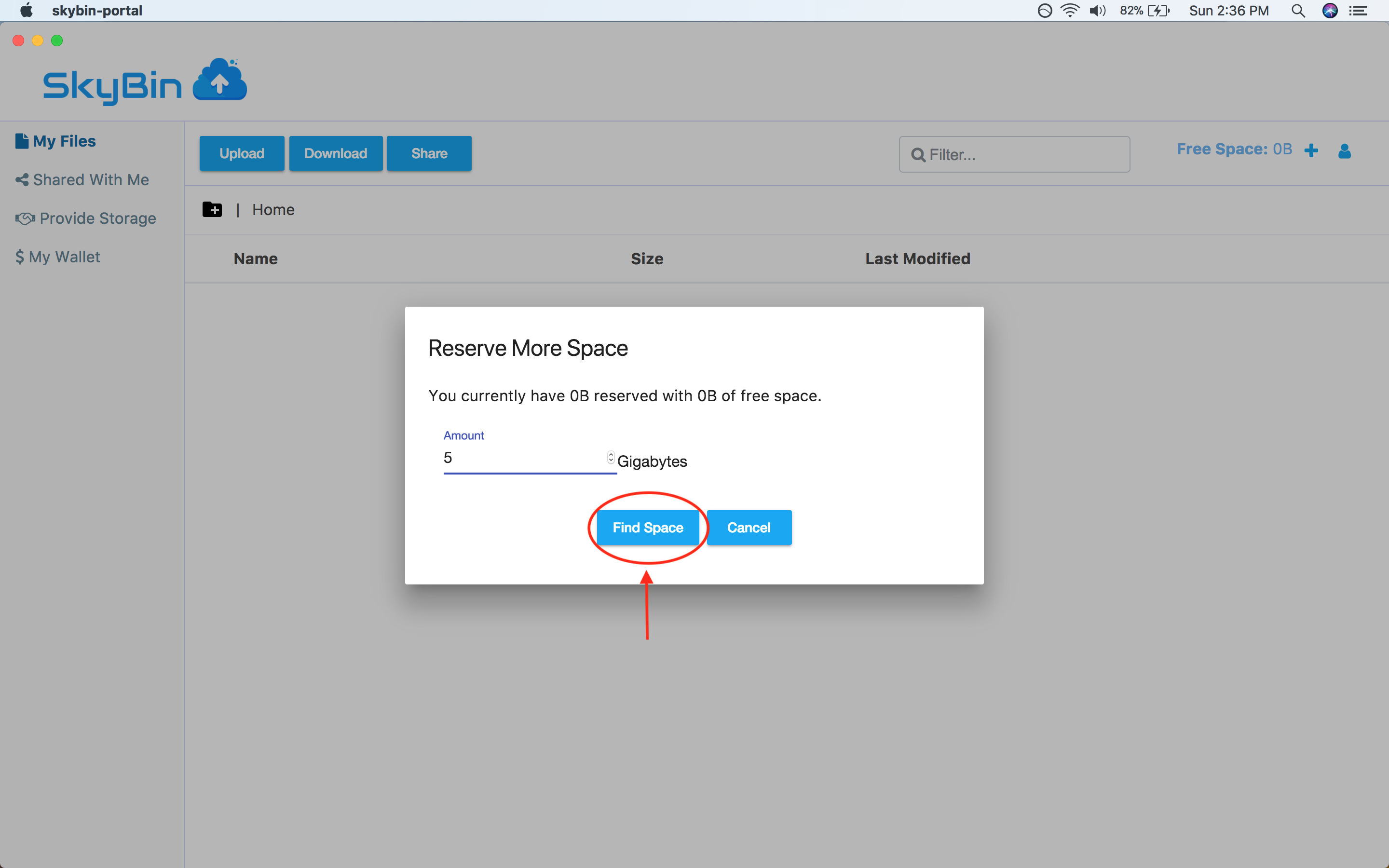
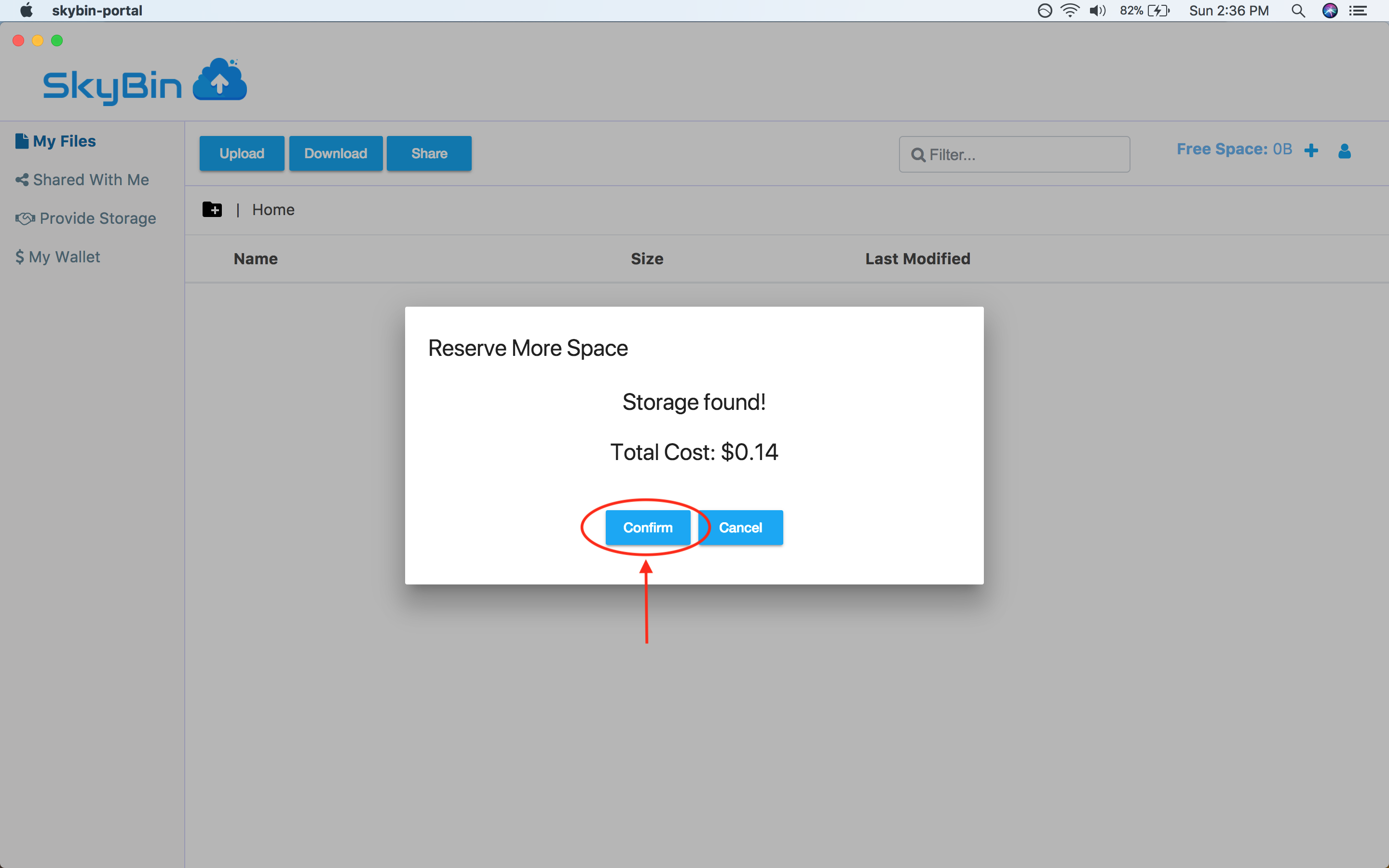
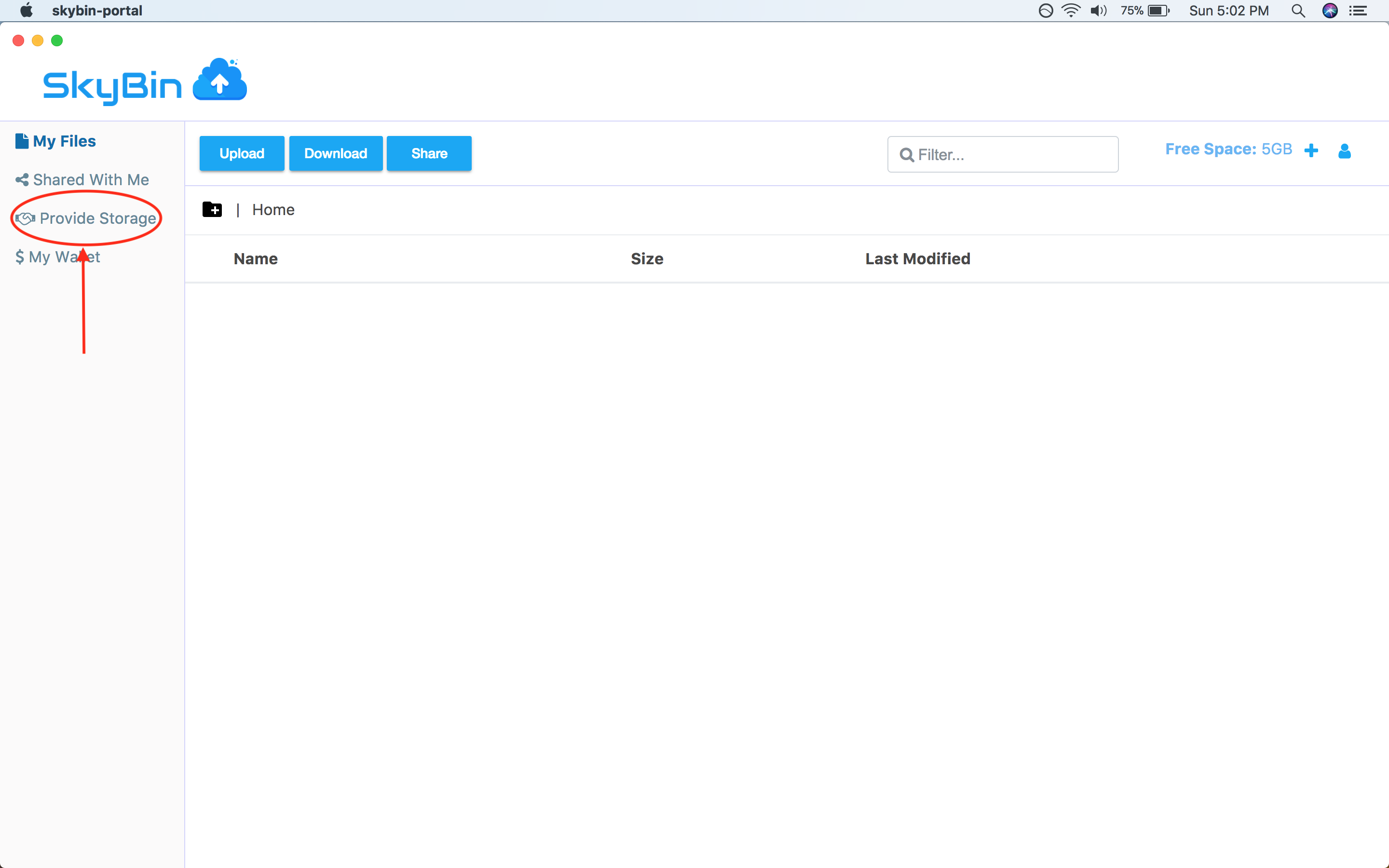
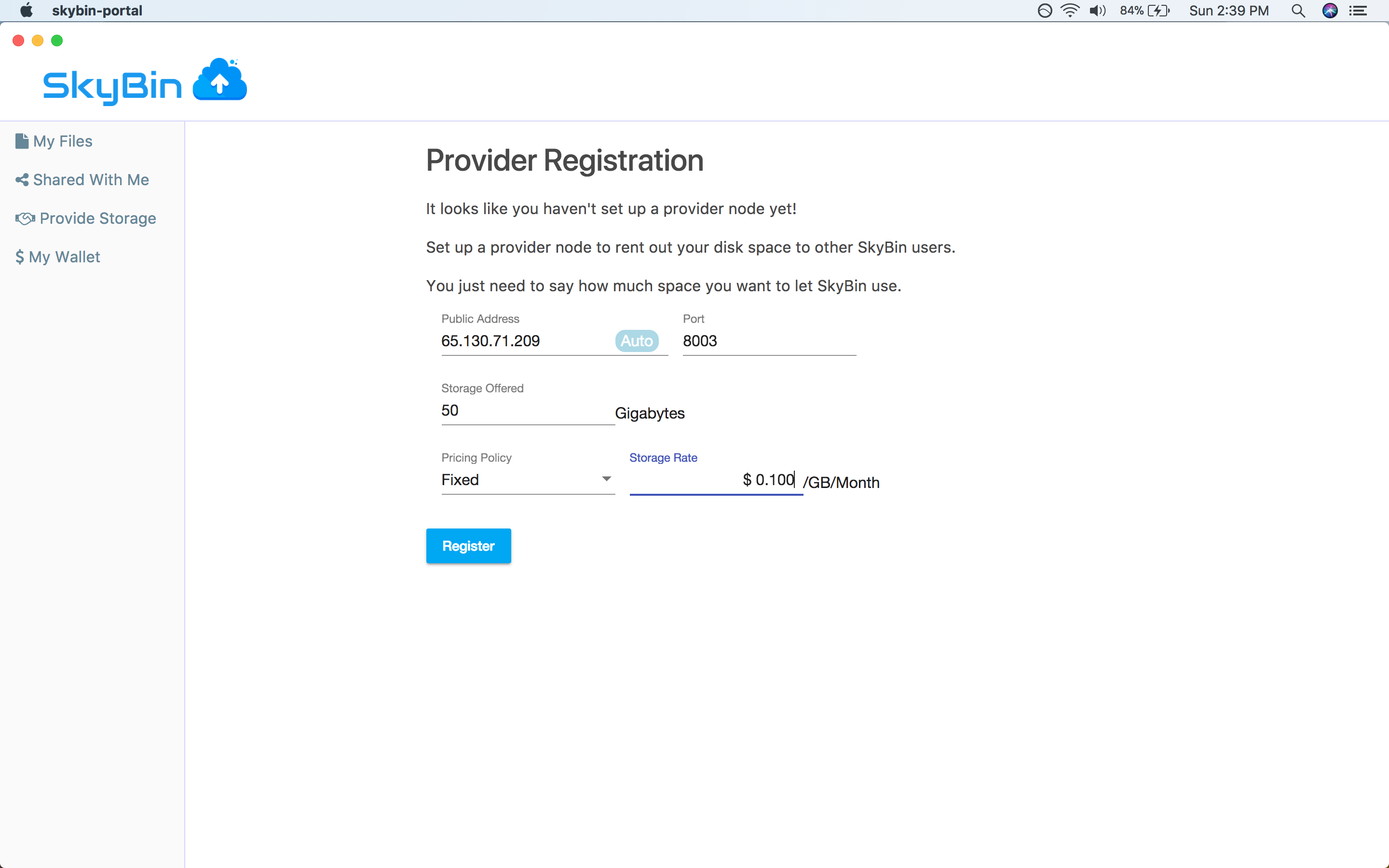
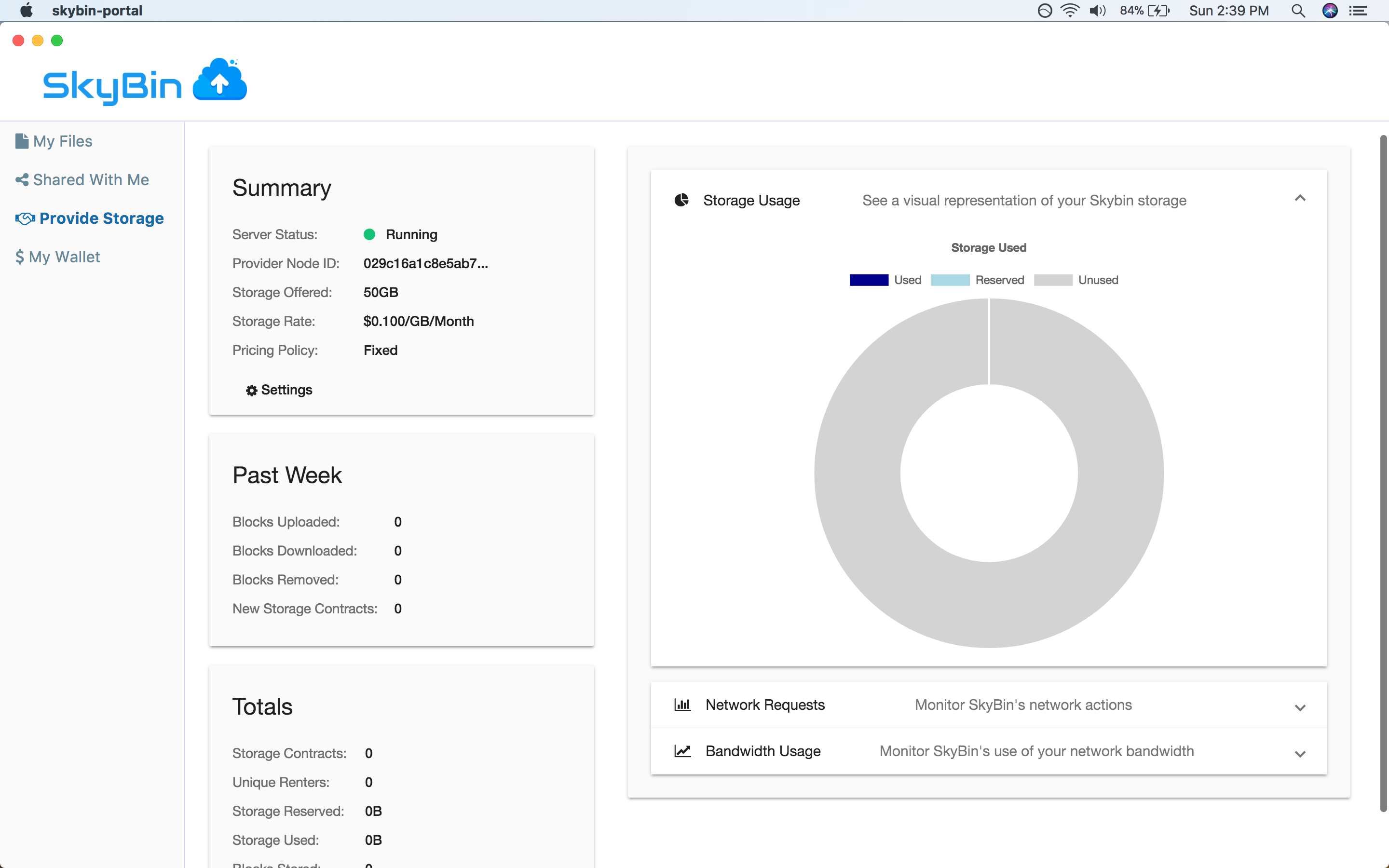
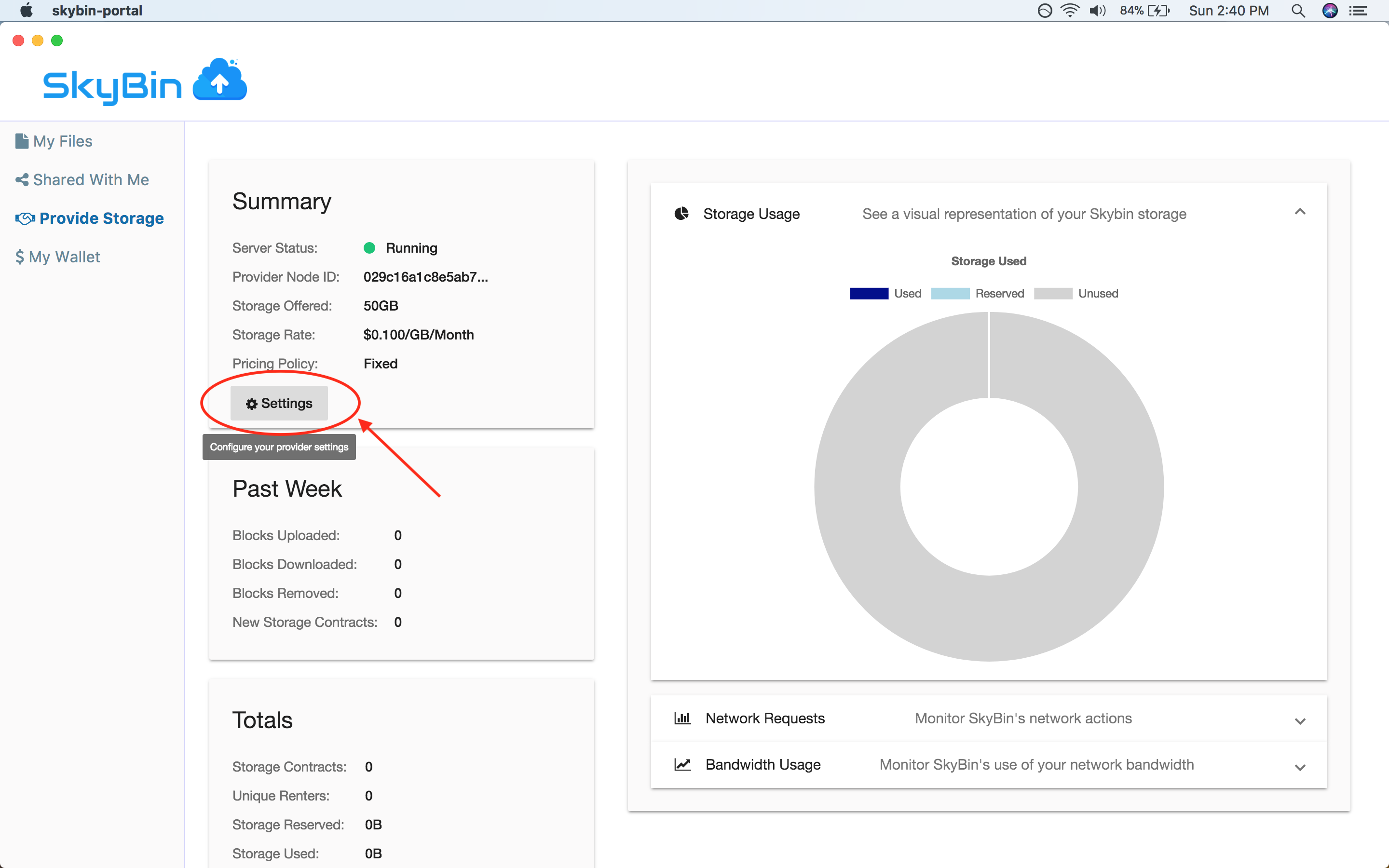
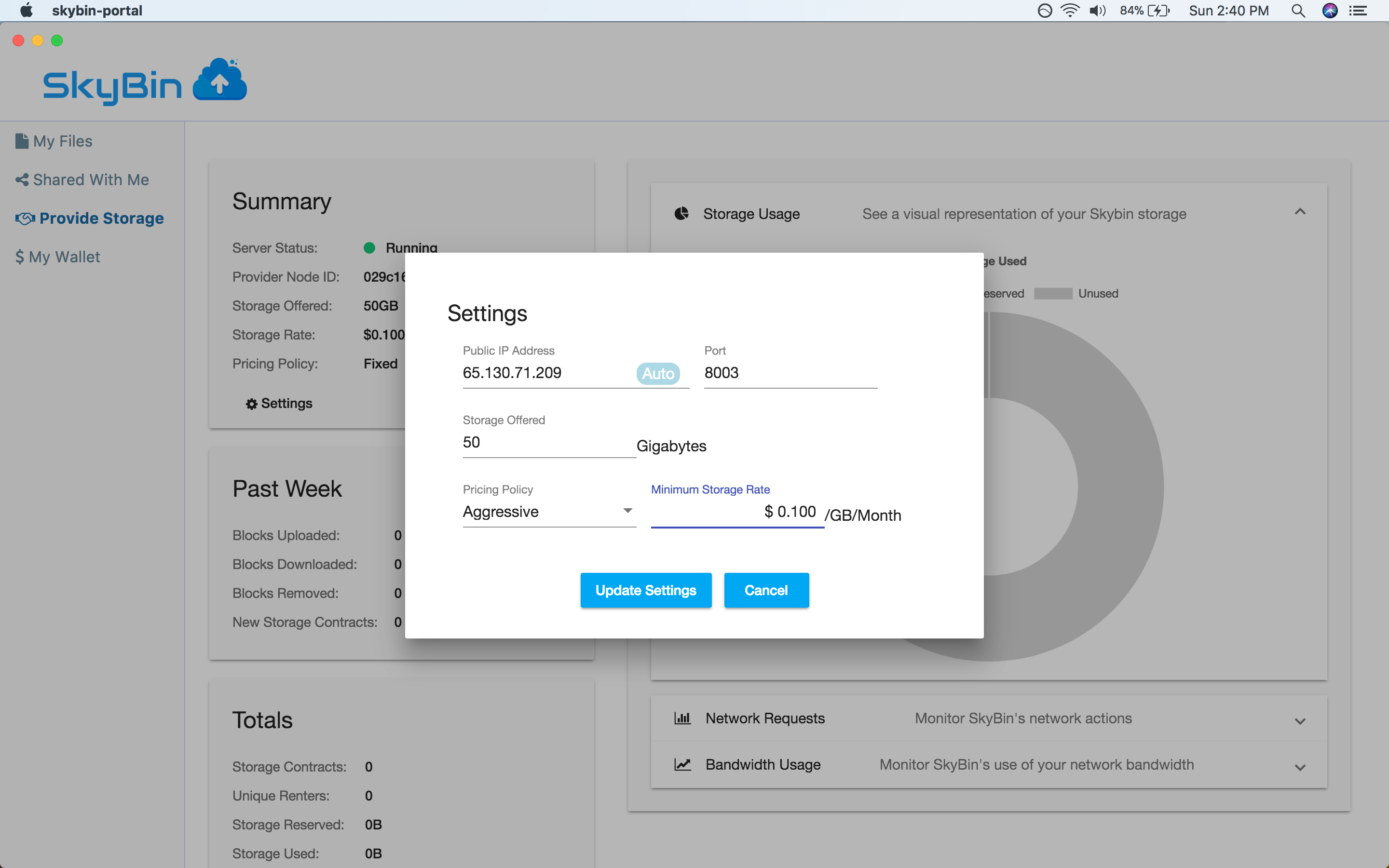
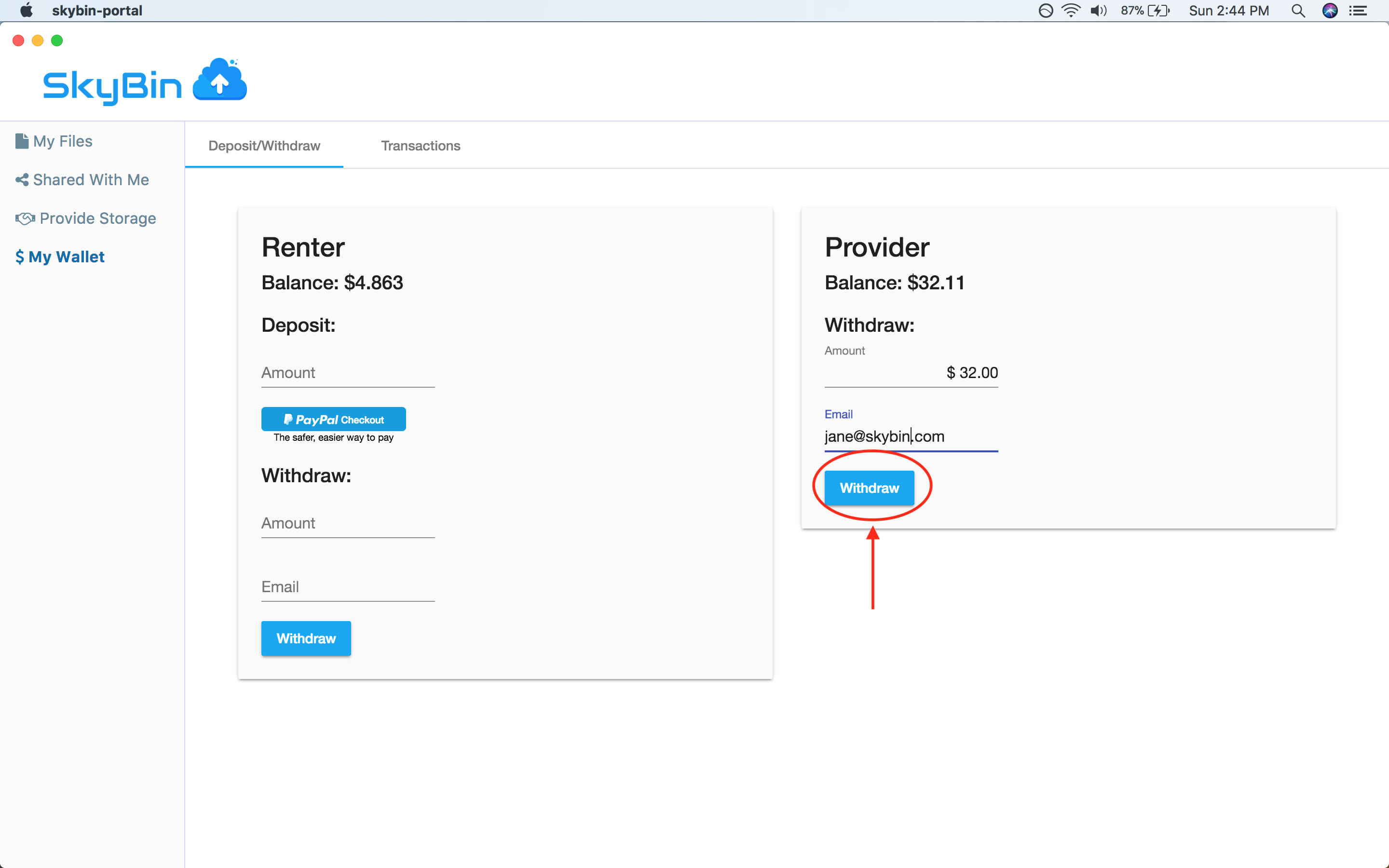
With SkyBin, you can also rent out your unused disk space to other users on the
network in return for cash. You get paid through Paypal, so it's easy to setup
and get started.